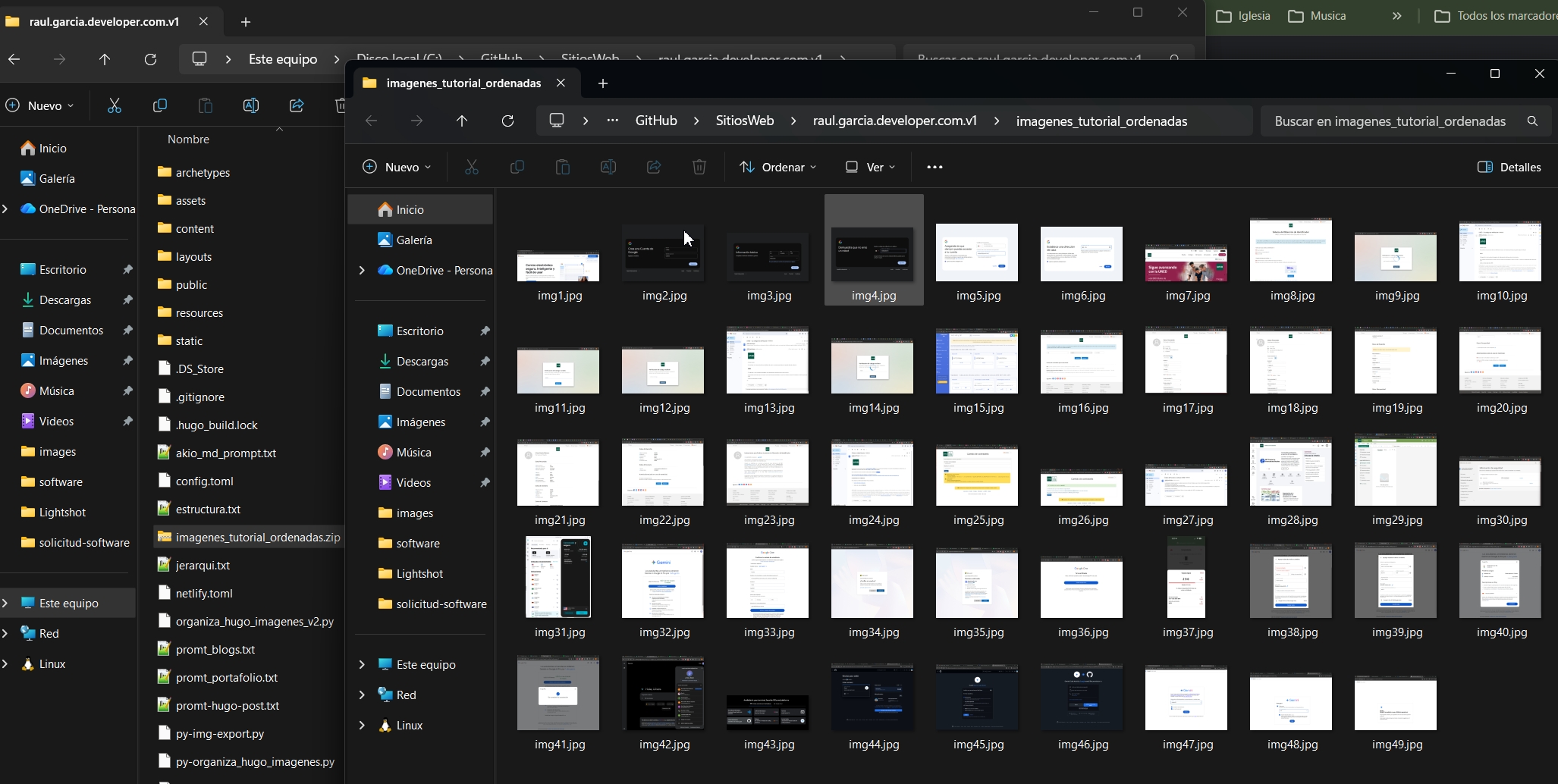
En el flujo de trabajo diario de un desarrollador o creador de contenido, es común recibir documentos de Word repletos de imágenes que necesitamos utilizar en la web. El método manual de “Guardar como imagen” es lento, y cambiar la extensión a .zip a menudo resulta en nombres de archivo desordenados (image15.png puede ser la primera imagen visualmente).
En este artículo, comparto un script de Python que he desarrollado para resolver este problema: analiza la estructura XML interna del documento y extrae las imágenes respetando estrictamente el orden visual de lectura.
1. Requisitos del Sistema
Para ejecutar esta automatización, necesitamos preparar el entorno. A continuación, detallo los comandos necesarios para Windows (PowerShell).
A. Instalación de Python
Si aún no cuentas con Python, utiliza Winget (el gestor de paquetes de Windows) para una instalación limpia:
winget install -e --id Python.Python.3
Nota: Es recomendable cerrar y volver a abrir tu terminal tras la instalación para refrescar las variables de entorno.
B. Instalación de Librerías
Utilizaremos Pillow para el procesamiento de imágenes y lxml para el análisis robusto de archivos XML. Ejecuta el siguiente comando:
python -m pip install pillow lxml
2. El Script de Automatización
Guarda el siguiente código en un archivo llamado img-export.py.
Este script no se limita a descomprimir; lee el archivo document.xml interno de Word para crear un mapa de las imágenes tal como aparecen en el documento, evitando errores de numeración.
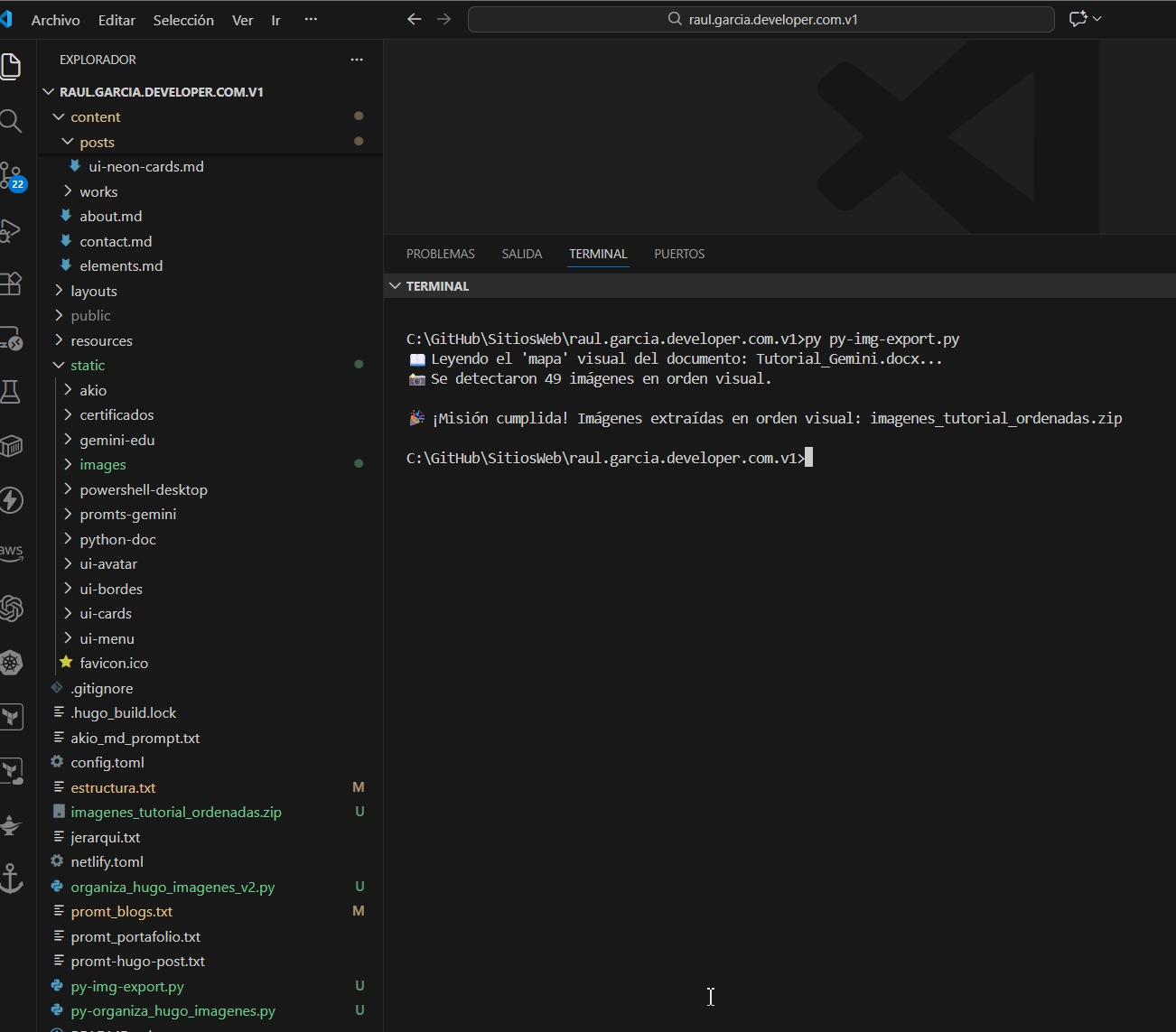
import zipfile
import os
import shutil
import xml.etree.ElementTree as ET
from PIL import Image
import io
import re
def exportar_imagenes_orden_visual(docx_path, output_zip_name):
"""
Extrae imágenes de un archivo .docx respetando el orden visual de aparición.
"""
temp_dir = "temp_img_visual"
# Limpieza de entorno: eliminar carpeta temporal si existe
if os.path.exists(temp_dir):
shutil.rmtree(temp_dir)
os.makedirs(temp_dir)
print(f"📖 Analizando estructura visual de: {docx_path}...")
try:
with zipfile.ZipFile(docx_path, 'r') as z:
# 1. Mapeo de Relaciones (ID -> Archivo)
rels_xml = z.read('word/_rels/document.xml.rels')
rels_root = ET.fromstring(rels_xml)
id_to_filename = {}
# Namespace para relaciones en Office Open XML
ns_rel = '{http://schemas.openxmlformats.org/package/2006/relationships}'
for rel in rels_root.findall(f'{ns_rel}Relationship'):
r_id = rel.get('Id')
target = rel.get('Target')
if 'media/' in target:
id_to_filename[r_id] = os.path.basename(target)
# 2. Análisis del Documento (Orden de aparición)
doc_xml = z.read('word/document.xml')
doc_root = ET.fromstring(doc_xml)
# Namespaces requeridos para parsear los tags de Word
namespaces = {
'r': 'http://schemas.openxmlformats.org/officeDocument/2006/relationships'
}
ordered_images = []
# Iteramos sobre el árbol XML buscando referencias a imágenes
for elem in doc_root.iter():
embed_id = None
# Soporte para tags modernos (blip) y legacy (imagedata)
if elem.tag.endswith('blip'):
embed_id = elem.get(f"{{{namespaces['r']}}}embed")
elif elem.tag.endswith('imagedata'):
embed_id = elem.get(f"{{{namespaces['r']}}}id")
if embed_id and embed_id in id_to_filename:
ordered_images.append(id_to_filename[embed_id])
if not ordered_images:
print("⚠️ No se detectaron imágenes en el cuerpo del documento.")
return
print(f"📸 Procesando {len(ordered_images)} imágenes en secuencia...")
# 3. Procesamiento y Renombrado
contador = 1
for original_name in ordered_images:
zip_path = f"word/media/{original_name}"
try:
img_data = z.read(zip_path)
img = Image.open(io.BytesIO(img_data))
# Convertir PNGs transparentes a RGB para evitar errores en JPG
if img.mode in ('RGBA', 'P'):
img = img.convert('RGB')
# Nomenclatura secuencial: img1.jpg, img2.jpg...
new_filename = f"img{contador}.jpg"
save_path = os.path.join(temp_dir, new_filename)
with open(save_path, 'wb') as f:
img.save(f, 'JPEG', quality=95)
contador += 1
except Exception as e:
print(f" ❌ Error en recurso {original_name}: {e}")
# 4. Generación del ZIP Final
with zipfile.ZipFile(output_zip_name, 'w', zipfile.ZIP_DEFLATED) as zipf:
for root, dirs, files in os.walk(temp_dir):
# Ordenamiento natural para el ZIP (1, 2, 10...)
files.sort(key=lambda f: int(re.findall(r'\d+', f)[0]))
for file in files:
zipf.write(os.path.join(root, file), arcname=file)
print(f"\n🎉 ¡Éxito! Archivo generado: {output_zip_name}")
except Exception as e:
print(f"❌ Error crítico: {e}")
finally:
if os.path.exists(temp_dir):
shutil.rmtree(temp_dir)
# Punto de entrada
if __name__ == "__main__":
# Configuración de archivos
input_file = "Tutorial_Gemini.docx"
output_file = "imagenes_tutorial_ordenadas.zip"
exportar_imagenes_orden_visual(input_file, output_file)
3. Instrucciones de Ejecución
- Coloca tu archivo de Word (en este ejemplo
Tutorial_Gemini.docx) en la misma carpeta que el script. - Abre tu terminal en dicha ubicación.
- Ejecuta el script:
python img-export.py
Al finalizar, encontrarás un nuevo archivo .zip en tu directorio conteniendo todas las imágenes perfectamente numeradas (img1.jpg, img2.jpg…) listas para ser integradas en tu próximo post o proyecto web.